Olemi-suhte diagramm ja andmebaaside loomine
Olemi-suhte diagramm (ERD - Entity Relationship Diagram) on kõige laiemalt levinud metoodika andmemudelite koostamiseks ja kirjelduse esitamiseks. Tegemist on pool-formaalse mudeliga, kus on ühendatud:
- andmemudeli graafiline esitus - olemid (entity), vaated (views) ja nende vahelised seosed (relationships)
- tabelite sisemise struktuuri formaalsed kirjeldused (olemite atribuudid, atribuutide andmetüübid, piirangud, indeksid)
- vaadete formaalsed kirjeldused (kuidas vaated olemite kaudu kirjelduvad)
- olemite ja vaadete vaheliste seoste formaalsed kirjeldused (seoste väljade kirjeldused, seose tugevuse kirjeldused)
- mudeli komponentide verbaalsed kirjeldused (olemite, atribuutide, seoste, protseduuride jm. semantika vabatekstiline kirjeldus)
Kogu andmebaasi loomise protsess toimub järgmiselt. Kõigepealt koostatakse andmemudel. Seda tehakse just nii täpselt, kui seda parasjagu on vaja. Seejärel koostatakse loodud mudeli alusel SQL-laused, mille abil luuakse füüsiline andmebaas. Kui nüüd aja jooksul selgub, et andmebaasi struktuuris on vaja teha muudatusi, siis täiustatakse/muudetakse ERD mudelit ja seejärel luuakse muudetud mudeli alusel SQL-laused, mille abil muudetakse andmebaasi struktuur vastavaks loodud mudelile. jne. kuni "lõpmatuseni"
Tegelikkuses on peale andmebaasi struktuuri muutmise veel vaja teha olulisi tegevusi. Ei ole ju andmebaasid nende struktuuri muutuste ajal tühjad, vaid seal on andmed, mille säilivus tuleb tagada ka pärast muutusi. Seepärast tuleb enne andmebaasi struktuuri muutmist tõsta sellese andmebaasi osa, kus tehakse muudatusi, andmed andmebaasist välja (backup) ja pärast andmete struktuuri muutust tuleb olemasolevad andmed paigutada uuele struktuurile.
Tänu ERD mudeli heale formaliseeritusele on selle loomise ja haldamise tarvis võimalik päris hästi teha ERD-l põhinevaid andmete modelleerimist toetavaid CASE-süsteeme. See võimaldab kogu andmete modelleerimise ja andmebaaside loomise ning andmestruktuuride haldamise/muutmise protsessi väga hästi ära automatiseerida. Kõigepealt luuakse andmebaasi andmemudeli ERD-l põhinev kirjeldus. Loodud olemi-suhte diagrammi alusel genereeritakse andmebaasi loomise käsud. Tavaliselt on andmebaasi kirjeldamise keeleks SQL-keel. Olemite kirjeldustest genereeritakse tabelite kirjeldused. Olemi atribuutide kirjelduste alusel genereeritakse tabelite veergude kirjeldused. Vaadete ja indeksite kirjeldustest genereeritakse andmebaasi vaated ja indeksid. Olemite ja vaadete vaheliste seoste kirjeldustest genereeritakse andmebaasi seosed. Pärast loodud SQL-keelse kirjelduse käivitamist andmebaasis ongi tühi andmebaas loodud.
Kui nüüd on vaja andmebaasi struktuuri muuta, tehakse vajalikud muudatused ERD-mudelis. Seejärel võrreldakse CASE-süsteemi abil uut mudelit olemasoleva andmebaasi struktuuriga ja genereeritakse SQL-keelsed andmebaasi andmestruktuuri muutmise laused. Loodud laused täidetakse andmebaasisüsteemis ja pärast muutuste tegemist viiakse eelnevalt andmebaasis olnud andmed vastavusse uue struktuuriga
4.2. ERD komponendid. ERD-ga seotud mõisted
ERD põhilisteks komponentideks on olemid (vastavad andmebaasi tabelitele) ja olemite vahelised seosed (vastavad tabelite vahelistele seostele andmebaasides). Olemite enda sisemine struktuur koosneb atribuutidest (vastavad andmebaasi tabeli veergudele). Seoste kirjeldus koosneb seotud olemite nende atribuudi paaride kirjeldustest, mis kirjeldavad seose kahe olemi vahel. Seos saab olla kirjeldatud alati ainult kahe olemi vahel või siis olemi seosena ise endaga (sellisel juhul on seose mõlemas otsas see sama objekt - seos moodustab suletud tsükli selle ühe olemiga).
Olem on (andmekoosluse) määratlus, mis väljendab reaalse maailma mingile objektile, nähtusele, sündmusele või reaalse maailma objektide seosele vastavat loogilist üldmõistet (kirjeldust). Olem on kompleksne mõiste mis hõlmab endas kogu antud temaatikaga seotud kirjeldust. Kui olemile on kirjeldatud ka sisemine struktuur, siis “kirjeldab olem maailm” ainult nendes piirides, mida olemi sisemine struktuur võimaldab.
Näide: Näiteks väljendab olem “Auto” reaalse elu objektide kogumit “autod” ilma lahtimõtestamata, millist konkreetset autot me mõtleme (mingi auto, kõik teadaolevad autod, kõik autod, kõik “meie” autod, kõik antud protsessis osalevad autod)
Olemi-suhte diagrammi semantika, milles olem asub määrab olemiga kirjelduvatele objektidele mingid täpsemad piirid – autoregistri mudelis olev olem “Auto” tähistab kõiki registris olevaid autosid fikseerituna nende omadustega, mis vastava registri seaduses on ette nähtud.
Näide: Näiteks väljendab olem "Isik" reaalse elu objektide kogumit "isikud" ilma lahti mõtestamata, milliseid konkreetseid isikuid me silmas peame (kõik maailma inimesed, kõik eesti kodanikud, kõik Eesti pinnal olevad füüsilised ja juuriidilised isikud ning FIEd vms.) Kui me nüüd aga ütleme, et tegemist on Eesti kodanike registri olemi-suhte diagrammiga, siis kirjeldub olem "Isik" kohe hulga täpsemalt, sest Elanikkonna registri seaduses on väga täpselt kirjas, kes tohivad sellesse registrisse kuuluda (ainul kodanikud ja pikaajalise elamisloa alusel Eestis viibivad isikud) ja millised andmed iga registrisse kuuluva isiku kohta tuleb talletada.
Näide: Olem “Abileu” väljendab seost kahe inimese vahel, millel on alguskuupäev, lõpukuupäev, seost reglementeeriv seadusandlus ja võib-olla ka abieluleping (või vara lahususe leping). Selline olem omab tähendust ainult kas riikliku abiuluregistri või mõne kiriku infosüsteemi olemi-suhte diagrammis. See olem eeldab muidugi ka seda, et kusagil üsna lähedal asub olem "Isik".
Igal olemil on semantika, mis kirjeldab olemi olemust ja toimimist. Olemi semantika on olemi verbaalne (“jutustav”) kirjeldus, milles kirjeldatakse olemi seos reaalse maailmaga ning olemi ilmingute andmebaasi tekkimise, nende muutumise ja hävitamise reeglid.
Näiteks võib olemi “Auto” semantika olla järgmine – autoregistrisse kantavate autode teatmik, kuhu auto tekkib siis, kui ta esimest korda arvele võetakse. Muutused auto andmetes tehakse siis, kui muutub tema kere number (kere remondi käigus), värv (värvitakse üle), mootori number (mootor vahetatakse) või vahetatakse auto registrinumbrit. Auto mark, mudel ja väljalaskeaasta ei saa muutuda. Autot ei kustutata registrist füüsiliselt kunagi – kui auto võetakse registrist arvelt, kas maha kandmiseks või välismaale müügiks, siis tehakse autole sellekohane märge.
Olemit võib vaadelda kontseptuaalsel tasemel st. ilma tema sisemist struktuuri täpsustamata rahuldudes lihtsalt olemi semantika tundmisega. Andmemudelite projekteerimise alguses vaadeldaksegi kõiki, või vähemalt enamusi olemeid, kontseptuaalsel tasemel. Sellist ERD mudelit, kus olemite sisemine struktuur ei ole veel täpsustunud nimetatakse infoloogilisteks mudeliteks. Infoloogilistes mudelites koosneb ERD omavahel seostatud olemitest, mida tähistavad vaid ristküliku sisse kirjutatud olemite semantilised nimed:

See skeem kirjeldab vara ja isikute vahelisi seoseid. See kas me teame skeemil kirjeldatud olemite sisemist struktuuri ei aita meil paremini mõista antud skeemi kontseptuaalset tähendust. Olulisem on teada, millised on skeemil toodud olemite semantikad. Oluline on näiteks teada, milliseid isikuid seob olem ISIK. On seal ainult füüsilised isikud või kuuluvad sinna ka firmad, mittetulundusühingud, parteid ja FIE'd. Oluline on teada, millised objektid kirjelduvad olemis OBJEKT. On seal ainult kinnisvara või ka vallasvara. Olemi VARA OMAMINE puhul on oluline teada, kas selle olemiga kirjeldatakse ainult kehtivad omandussuhted või hoitakse seal ka omanduse ajalugu. Andmemudeli kontseptuaalse mudeli loomisel on vaja vastata just sellistele küsimustele. See kõik on täiesti piisav selleks, et projekteerida vajalikud olemid ja nende vahelised seosed. Atribuudid (olemite sisemise struktuuri) võib kirjeldada alles pärast seda, kui infoloogiline mudel on valmis.
Pärast seda kui olemite semantika on kirjeldatud "tekkib" semantika kirjeldatud seostele. Olemite ISIK ja VARA OMAMINE vahel oleva seose semantikaks on "isiku poolt omatav või kunagi omatud kinnisvara" ja tabelite VARA ning VARA_OMAMINE vahelise seose semantikaks on "isikud, kes omavad seda kinnisvara praegu või on kunagi omanud seda". Kui kahe olemi vahele on kirjeldatud seos, kuid selle semantikat pole võimalik verbaalselt kirjeldada, siis ilmselt on tegemist valesse kohta joonistatud seosega.
Oletame, et me tahame luua kinnisvara omanike registrit. Sellisel juhul kirjeldame me olemi VARA, kui kõigi kinnisvaraobjektide kogumi. Olem ISIK kirjeldab kõiki selliseid inimesi, kellel on praegu kinnisvara, või kelle seda varem on olnud. Seejuures tuleb lisapiiranguna määrata kindlaks, kas me tahame iga olemis registreeritud kinnisvara objekti kohta registreerida selle kõik varasemad omanikud või mitte. Esimesel juhul on isikute ring oluliselt laiem kui teisel juhul. Kinnisvara registri korral peame me lisaks kehtivatele omandussuhetele säilitama ka omandussuhete ajaloo minevikus.
Vaatame nüüd ülal toodud ERD mudelit (kontseptuaalset skeemi) kirjeldatud piirangute valguses. Pärast mudeli, olemite ja olemite vaheliste seoste semantika kirjeldamist on joonisel toodud ERD skeem tunduvalt konkreetsem ja täpsemini määratletud. Sellise taseme kirjelduse alusel võime me juba üpris kindlalt hinnata skeemi vastavust vajadustele.
Pea mitte kunagi ei joonistata ERD skeemi lõpuni ilma olemite sisemist struktuuri kirjeldamata. Ikka on olemitel mingeid selliseis omadusi, mille kirjeldamine juba mudeli kontseptuaalsel tasemel annab mudelile olulist informatsiooni juurde. See ei muuda aga kontseptuaalse (infoloogilise) mudeli olemust. Atribuudid, mis kirjeldatakse olemitele olemite oluliste omaduste kirjeldamiseks täidavad sellisel juhul teist eesmärki. - nad ei kirjelda mitte niivõrd olemi sisemist struktuuri kuivõrd on olemite semantilise kirjelduse komponentideks. Olemi struktuuri komponentideks muutuvad nad pärast olemi täieliku struktuuri projekteerimist.
Pärast andmemudeli semantiliste mudeli (infoloogilise mudeli) koostamist tuleb see viia andmeloogilisele tasemele. Andmeloogilise modelleerimise käigus projekteeritakse olemite sisemine struktuur, mis koosneb olemi omadustest ja mille väljenduseks ERD-mudelis on olemi atribuudid:

Siin joonisel on projekteeritud olemite atribuudid. Atribuut on olemi kirjelduse madalaim tase, millede kogum kirjeldab olemi struktuuri. Iga atribuudi juures tuleb kirjeldada ka atribuudi semantika - kirjeldus, milles määratakse, milliseid väärtusi kirjeldatav atribuut võib omandada, millal ta neid väärtusi võib omada ja mille tulemusena need väärtused muutuvad (kui nad muutuda võivad).
Sellega projekteerimine veel ei lõppe. Selleks, et andmeloogilise mudeli alusel luua reaalselt eksisteeriv andmebaas, tuleb andmeloogilise kirjelduse alusel viia läbi füüsiline modelleerimine. Kuni selle hetkeni läbi viidud modelleerimine on olnud üsna sõltumatu reaalsetest andmebaasisüsteemidest, mida tulevikus rakendatakse loodud mudeli alusel reaalsete andmebaasi loomiseks. Füüsilise modelleerimise käigus saab andmemudelist andmebaasi skeem so. skemaatiline kirjeldus, mille alusel saab luua andmebaasi.
Füüsilise modelleerimise käigus lisatakse andmeloogilise andmemudelile (minimaalselt) järgmised kirjeldused:
- olemitele tabelite nimed, mille all olemite kirjelduse järgi luuakse andmebaasi tabelid
- olemitele seoste võtmete kirjeldused (primaarvõtmed ja välisvõtmed)
- olemitele indeksite kirjeldused
- olemite atribuutidele veergude nimed, mille all olemite kirjelduse järgi luuakse andmebaasi tabelite veerud
- olemite atribuutidele andmetüübid, pikkused ja NULL NOT NULL piirangud
Siin joonisel on näha, et kõikidele atribuutidele on lisatud andmetüübid, pikkused ja NULL/NOT NULL piirang, mis määrab, kas antud atribuut võib olla mõnes kirjes tühi (NULL) või mitte (NOT NULL). Tabelitele on kirjeldatud ka indeksid, kuid need kirjeldused ei paista skeemi peal välja.
4.3. Seosed olemite vahel. Üks-mitmene seos
Valdav osa (üle 99%) seostest olemite vahel on nn. just sellised "üks-mitmesed" seosed (üks - null, üks või mitu):

Joonisel toodud sümbol on võetud metoodikast mida tuntakse IE (Information Engereering) all . On veel teisi tähistusi, kuid nendest räägime hiljem. Siin jaotuses toodud notatsioon on enim kasutatud ja ilmselt ka parim seni välja töötatud notatsioonidest.
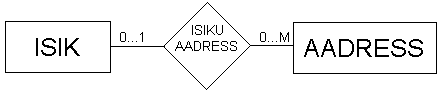
Igal komponendil selle suhte kujutise peal on oma kindel tähendus. Nendest komponentidest saab kokku panna mitmeid erinevaid kombinatsioone, milledest igal on oma sügav tähendus. . Vaatleme neid kombinatsioone üks haaval. Et oleks lihtsam esile tuua iga konkreetse variandi iseärasusi kasutame lihtsat näidet isikute sidumisest aadressidega.
- seos: üks - üks või mitu
Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada igal juhul vähemalt üks aadress, aga tema kohta võib neid olla teada ka mitu. Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga. Ei ole võimalik, et eksisteerib isik, keele kohta pole teada ühtegi aadressi.

-
seos: üks - null, üks või mitu
Skeemil on kirjeldatud inimene (inimesed), kes võib eksisteerida nii, et tema kohta pole teada ühtegi aadressi. Me võime tema kohta siiski teada ühte või enamat aadressi. Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga.

-
seos: null või üks - üks või mitu Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada igal juhul vähemalt üks aadress, aga tema kohta võib neid olla teada ka mitu. On võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud ühegi isikuga.

-
seos: null või üks - null, üks või mitu Skeemil on kirjeldatud inimene (inimesed), kes võib eksisteerida nii, et tema kohta pole teada ühtegi aadressi. Me võime tema kohta siiski teada ühte või enamat aadressi. Aadress võib eksisteerida ka iseseisvalt – ilma et ta oleks seostatud isikuga.

-
seos: üks - mitu VÄGA HARVA ESINEV !!! Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada igal juhul vähemalt kaks (mitu) aadressi, aga tema kohta võib neid olla teada ka rohkem. Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga. Ei ole võimalik, et eksisteerib isik, keele kohta pole teada vähemalt kahte aadressi.

-
seos: üks - null või mitu ERITI HARVA ESINEV !!! Skeemil on kirjeldatud inimene (inimesed), kellele kohta pole teada ühtegi aadressi või kui neid mõni teada on, siis on neid vähemalt kaks (mitu), aga tema kohta võib neid olla teada ka rohkem. Ei ole võimalik, et isiku kohta on teada ainult üks aadress. Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga.

-
seos: üks - üks ESINEB AINULT TEHNILISTEL KAALUTLUSTEL !!! Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada alati ainult üks aadress. Ei ole võimalik, et isiku kohta on teada rohkem kui üks aadress või et tema kohta pole teada ühtegi aadressi Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga. Nendes kahes olemis on alati võrdne arv kirjeid.
Sisuliselt on tegemist olukorraga kus loogiliselt ühe olemi atribuudid on jaotatud kahe olemi vahel. Üldjuhul tähendab see seda, et tegemist on kahe olemiga, mis asuvad erinevates andmebaasides. On veel ka võimalus, et olem on jagatud kaheks turva kaalutlustel - et oleks võimalik lubada/keelata erinevatel kasutajatel juurdepääsu erinevatele andmekooslustele ja tagada eriti kõrge turvalisuse tase füüsilise andmelahususega.
-
seos: üks - null või üks ESINEB AINULT TEHNILISTEL KAALUTLUSTEL !!!
Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada kuni üks aadress. Ei ole võimalik, et isiku kohta on teada rohkem kui üks aadress. Ei ole võimalik, et aadress eksisteerib iseseisvalt – ilma et ta oleks seostatud isikuga. Olemis ISIK on alati kas sama arv kirjeid kui olemis AADRESS või on neid seal rohkem kui olemis AADRESS.
Nagu eelmise seose variandi korral, kasutatakse ka sellist seost ainult tehnilistel kaalutlustel. Põhjus on aga eelmisest seose variandist erinev. Sellist seost kasutati palju siis, kui kõvaketaste maht oli väike ja seda tuli iga hinna eest kokku hoida. Seda õnnestus teha sellistel juhtudel, kui olemis oli atribuute, millele väärtused ilmnesid harva. Sellisel juhul koondati harva esinevate väärtustega atribuudid eraldi olemisse aj seoti see põhi olemiga selliselt, et kirje seotud olemisse tekkis ainult siis, kui oli sinna mingeid väärtusi kirjutada. Tühjade väärtustega kirjeid ei tekitatud ja seega hoiti mälu kokku.
-
seos: null või üks - üks ESINEB AINULT TEHNILISTEL KAALUTLUSTEL !!! Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada alati ainult üks aadress. Ei ole võimalik, et isiku kohta on teada rohkem kui üks aadress või et tema kohta pole teada ühtegi aadressi. Aadress võib eksisteerida iseseisvalt – ilma et ta oleks seostatud isikuga. Olemis AADRESS on alati kas sama arv kirjeid kui olemis ISIK või on neid seal rohkem kui olemis ISIK.
Tegemist on täpselt sama seosega, mida on kirjeldatud punktis 8 ainsa vahega, et see on olemitevahel teist pidi. Ka kasutamise põhjendus on sama.
-
seos: null või üks - null või üks

Skeemil on kirjeldatud inimene (inimesed), kellele kohta on teada kuni üks aadress. Ei ole võimalik, et isiku kohta on teada rohkem kui üks aadress. Aadress võib eksisteerida iseseisvalt – ilma et ta oleks seostatud isikuga.
4-3-image014.png
olemi jaotamine kaheks olemiks mingi tunnuse (näiteks rolli) alusel
Kuna ettevõtte töötajad võivad olla ka sama ettevõtte kliendid, siis sellisel juhul on sama isiku andmed registreeritud mõlemas olemis. Kui nüüd soovitakse näidata, millised on erinevates olemis olevate samade inimeste andmed, siis seostatakse sama inimese andmed mõlemas olemis.
Skeem kirjeldab olukorda, kus kõik firma töötajad pole sama firma kliendid ja kõik firma kliendid pole sama firma töötajad. Samas vastupidi asja vaadates on osad firma töötajad ka sama firma kliendid ja osad firma kliendid sama firma töötajad. -
rekursiivne seos Iga osakond võib olla teise osakonna alguses (aga ei pruugi). Igal osakonnal võib olla suvaline hulk alluvaid osakondi, aga ei pruugi olla. Tühja seose võimalikkust tähistavad “mullid” PEAVAD siin olema mõlemas suhte otsas sest – kõige alumisel tasemel on osakonnad, millele ei allu enam osakondi ja kõige ülemisel tasemel on osakonnad, mis ei allu ühelegi teisele osakonnale. Kui tegemist on juhtimispüramiidiga, siis on ülemus-osakondi, mis ei allu ühelegi teisele osakonnale, ainult üks.

Siin tuleb tähelepanu juhtida sellele, et rekursiivne seos saab olla ainult "null või üks - null, üks või mitu" ja MITTE KUNAGI teistsugune. Antud näites on alati olemas vähemalt üks osakond, millel pole ülemust (näiteks "Juhatus") ja alati on teatud hulk kõige madalamal tasemel olevaid osakondi, millele ei allu enam ühtegi teist osakonda.
Nüüd mõned näited seostest, mida ei ole olemas.
-
määratlemata seos

Seose otsas “üks” puudub “kriips”, mis tähistab “ühte” ja seega on seos määratlemata (olenemata sellest , mis on seose “mitmeses” otsas). Vahel kasutatakse seda siiski ka lihtsalt määratlemata seose kirjeldamiseks. Seda skeemi joonistamise väga varajases staadiumis tähistamaks seda, et kõik ei ole veel lõpuni läbi mõeldud -
olematu seos

Seose otsas “üks” ei saa olla ainult seose puudumise võimalikkust tähistav “mull” (olenemata, mis on seose “mitmeses” otsas). Praegusel kujul on tegemist seosega, mida kunagi ei eksisteeri, kuna tema otsas “üks” eksisteerib ainult variant, kus seos puudub.
4.4. Mitu mitmene seos
Kui vaadata eelmise jaotise alguses kirjeldatud sümboolikat olemite vaheliste seoste kirjeldamiseks, siis tekkib kindlasti küsimus, kas pole võimalik ehk joonistada mõnda sellist seost:
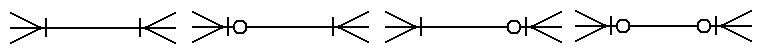
Sellele küsimusele võib vastata nii "ei" kui "jah". "Jah" tähendab seda, et väga kõrge üldistuse tasemega infoloogilistes mudelites võime me seda kasutada. "Ei" peame ütlema aga siis, kui üritatakse kasutada sellist seost andmebaasi füüsilise skeemi kirjeldamisel - andmebaasides sellist seost vähemasti sellisel kujul realiseerida ei õnnestu.
Vaatame seda asja nüüd lähemalt. Võtame kasutusele jälle kas olemit ISIK ja AADRESS:

On ju täiesti loogiline, et ühel isikul võib olla üks või mitu aadressi ja samas ei pruugi tal neid olla ühtegi. Teiselt poolt võib samal aadressil elada üks või mitu isikut aga samas on kindlasti aadresse kus ei ela kedagi. Kuna infoloogilise mudeli kirjeldamisel on olulisim semantika, siis võime me loomulikult selliseid seoseid kasutada.
Andmebaasi mudelite kirjeldamisel on aga asi sootuks teistsugune - siin peab lisaks toimivale semantikale olema olemas veel toimiv füüsiline struktuur. Sellisel kujul joonistatud mitu-mitmest suhet ei ole võimalik andmebaasis aga kirjeldada. Miks? Vaatame asja lähemalt.
Kui kaks tabelit on andmebaasi omavahel seotud, siis viiakse suhte "üks" otsas oleva tabeli primaarvõti üle suhte "mitu" poolses olevasse tabelisse:
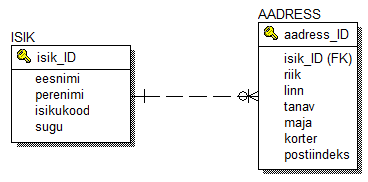
Nagu näha on tabeli ISIK primaarvõti olemas ka tabelis aadress aga siin on ta välisvõtmena (FK - foreign key). Kui tabelis ISIK on isik_ID unikaalne, siis tabelis AADRESS pole ta seda mitte. Tabelis ISIK olev iga kirje saabki olla tabeli AADRESS mitme kirjega olla seotud seeläbi, et igas temaga seotud kirjes on veerus isik_ID selle tabeli ISIK kirje isik_ID väärtus, millega tabeli AADRESS kirje seotud on. Siit võime tuletada reegli üldistuse selle jaoks, kuidas seos tekitatakse - seose tekitamisel kahe tabeli vahel toimub selliselt, et seose "üks" poolses otsas oleva olemi primaarvõtme väli kantakse üle suhte "mitu" poolsesse tabelisse.
Mõtleme, mis nüüd juhtub, kui me teeme suhte, mille mõlemad otsad on tüüpi "mitu". Kuna suhte "üks" poolne ots kadus ära, siis ei saa me rakendada just äsja välja mõeldud reeglit - pole lihtsalt suhte "üks" poolset otsa ja seega ei saa enam selle reegli järgi valida suhte liiget mille primaarvõti kantakse üle teise tabelisse. Sedasi ka ei saa, et ühe tabeli primaarvõtit teise tabelisse üldse üle ei kanna, sest siis ei tekki mingit seost kohe kindlasti. Kuna mõlemad suhte ostsad on võrdväärsed ja kuna ka suhte "mitmeses" otsas realiseerub ka vahel seos "üks", siis ainule loogiline järeldus võiks olla see, et tuleb mõlema tabeli primaarvõtmed viia üle teise tabelisse. Vaatame, mis sellest saab:
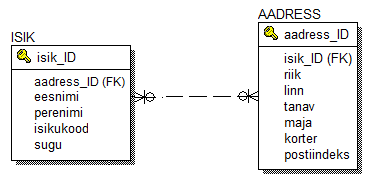
Kui nüüd üritada sellise skeemi abil teha mitu-mitmest seost, siis märkame, et saame mõlemale suhte poolele kirjutada ainult ühe teise poole ID väärtuse ja oleme seega sisuliselt loonud üks-ühese suhte. Kuidas siis asja lahendada? Mitu-mitmese seose kirjeldamiseks andmebaasis tuleb meil seos tabelite ISIK ja aadress vahel asendada uue tabeliga, mis on seotud mõlema tabeliga. See tabel kirjeldab mitu-mitmest seost. Selle tabeli semantikaks on selle seose semantika, mis tabeliga asendati. Uued seosed saavad aga veidi muudetud semantika:
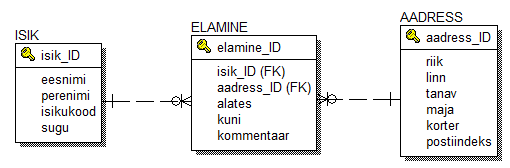
Uus tabel on seotud olemasolevate seostega teist pidi kui seda vanad tabelid oma vahel. Kui enne osutasid suhted "mitmese" otsaga tabeleid ISIK ja AADRESS, siis nüüd on tabelite ISIK ja AADRESS poole seoste "ühesed" otsad. Vaatame milline on uute seoste semantika. Tabelite ISIK ja ELAMINE vahel oleva seose semantika on "üks isik võib elada ühes või paljudes korterites või ei ela ta kusagil". Tabelite ELAMINE ja AADRESS vahel oleva seose semantika on " samal aadressil võib elada üks või palju inimesi või ei ela seal kedagi". Kui me nüüd võrdleme neid semantikaid enne suhte asendamist olemas olnud suhte semantikaga, siis märkame, et see semantika on just kui pooleks tehtud - suhte erinevate otste juures kirjelduv semantika on üle antud sellele seosele, mis asendab vana suhte vastavat otsa.
Mida kirjeldab nüüd siis uus tabel? Uus tabel kirjeldab seda, milline isik on millise aadressiga seotud ja millises ajavahemikus (alates - kuni). Siin ongi tegelikult selle asja mõte - mitu-mitmeste seoste korral on tähtis seoses olemise aeg ja vähemasti seda ei saanud me ilma uut tabelit lisamata kuidagi registreerida.
Iga kord, kui isiku ja aadressi vahele tekkib seos kirjeldatakse see tabelis ELAMINE selliselt, et näidatakse ära seotud isiku ja aadressi ID-d, ning kirjutatakse juurde ka see, mis ajast mis ajani seos kehtib - millal inimene selle aadressil elas või elab. Kui algus-kuupäev on minevikus ja lõpu kuupäev on määramata, siis on tegemist kehtiva seosega. Kui mõlemad kuupäevad on minevikus, siis on tegemist minevikus kehtinud seosega. Kui alguskuupäev on tulevikus on tegemist tulevikus jõustuva seosega.
4.5. ERD skeemide erinevad notatsioonid
Eelnevates jaotistes toodud näidetes kasutasime ERD skeemide joonistamiseks IE (Information Engeneering) sümboolikat (notatsiooni). See pole aga sugugi ainuke ERD notatsioon maailmas. Mõningase aimu andmiseks teistest notatsioonidest toome siin kohal lühikeste näidetena ära mõned tähtsamad:
IDEF1 (Integration DEFinition for Information Modeling)

See notatsioon on tähtis selle poolest, et tegemist on ISO standardiga. Täpsemalt saab selle notatsiooni kohta lugeda aadressilt http://www.idef.com/pdf/IDEF1MR-part1.pdf
Peter Chen'i notatsioon
Peter Cheni ERD notatsioonist saab täpsemalt lugeda aadressilt http://yourdon.com/strucanalysis/wiki/index.php?title=Chapter_12
Üsna nüansikas notatsioon töötati välja 1980 aastal James Martini juhatusel. Selle notatsiooni kohta saab täpsemalt lugeda aadressil: http://www.edrawsoft.com/Martin-ERD.php
4.6. ERD Case-süsteemid
Nagu juba ees pool mainitud on ERD Case süsteemid ette nähtud andmemudelite (ERD) joonistamiseks ja formaalseks kirjeldamiseks. ERD Case-süsteemide peamine funktsionaalsus on järgmine:
- andmebaaside skeeme mugav loomine ja muutmine (olemid, olemite atribuudid, olemite vahelised seosed)
- Kirjeldada andmemudeli füüsilisi parameetreid selleks, et nende alusel hiljem genereerida korraldused andmebaasi struktuuri loomiseks ja muutmiseks (tabelite nimed, veergude nimed, andmetüüp, pikkus, kohustuslikkus, andmekontrolli tingimused, esituskirjeldused, indeksite kirjeldused, vaadete kirjeldused jne.)
- andmemudeli erinevate komponentide semantika kirjeldamine
- erinevate raportite genereerimine loodud skeemide dokumenteerimiseks
- suurte skeemide osadeks jagamine ja nende osade seostamine
- genereerida loodud mudeli alusel andmebaaside loomise korralduste jadasid – samast skeemist saab genereerida korralduste jada erinevate andmebaasisüsteemide jaoks
- sünkroniseerida mudeli muudatused andmebaasidesse (muuta graafilise kirjelduse alusel andmebaaside struktuure) ja vastupidi (korrigeerida skeemi baasis tehtud muudatuste alusel
- andmebaasidest kirjelduste välja lugemine ja esitamine skeemina (olemi-suhte diagrammina)
- andmemudelite ühe andmebaasisüsteemi alt teise alla konverteerimine
- Töögruppide töö sünkroniseerimine
- Esitlusmaterjalide genereerimine
Mõned ERD Case-süsteemid (süsteemi nimi / firma):
- ErWin / Computer Associated
- ERStudio / Embarcadero
- Power Designer / Sybase
- DEFT / Deft Inc.